OpenAI 发布了 GPT-4o,更快、更强、更综合、更接近 AIGC,对所有 ChatGPT 用户免费
一、直播总结

刚刚结束的 OpenAI 春季更新直播发布会,OpenAI:
- 推出了最新、更快、更综合的AI大模型:GPT-4o,这是 GPT-4 模型的迭代版本。并有跨文本、语音和视觉的功能
- 所用用户可以免费使用GPT-4o,并且可以体验:
- 体验GPT-4级智能(免费用GPT-4)
- 超级丝滑的语音聊天对话体验(文本、语音、图像、视频综合能力)
- 从模型和网络获取响应(可以联网)
- 分析数据并创建图表 (数据分析)
- 聊聊你拍摄的照片(图像识别)
- 上传文件以帮助总结、写作或分析(文档识别与分析)
- 发现并使用 GPT 和 GPT 商店(免费使用GPTS)
- 使用 Memory 打造更有帮助的体验(带有记忆功能)
GPT-4o的“o”代表“omni”。该词意为“全能”,源自拉丁语“omnis”。在英语中“omni”常被用作词根,用来表示“全部”或“所有”的概念。
二、功能展示
原博客链接: https://openai.com/index/hello-gpt-4o/
推特链接: https://twitter.com/OpenAI/status/1790072174117613963 (推文下面有许多视频演示例子)
GPT-4o是迈向更自然人机交互的一步,它可以接受文本、音频和图像三者组合作为输入,并生成文本、音频和图像的任意组合输出,“与现有模型相比,GPT-4o在图像和音频理解方面尤其出色。”
在GPT-4o之前,用户使用语音模式与ChatGPT对话时,GPT-3.5的平均延迟为2.8秒,GPT-4为5.4秒,音频在输入时还会由于处理方式丢失大量信息,让GPT-4无法直接观察音调、说话的人和背景噪音,也无法输出笑声、歌唱声和表达情感。
与之相比,GPT-4o可以在232毫秒内对音频输入做出反应,与人类在对话中的反应时间相近。在录播视频中,两位高管做出了演示:
(10.590, -0.45, -4.08%)能够从急促的喘气声中理解“紧张”的含义,并且指导他进行深呼吸,还可以根据用户要求变换语调。
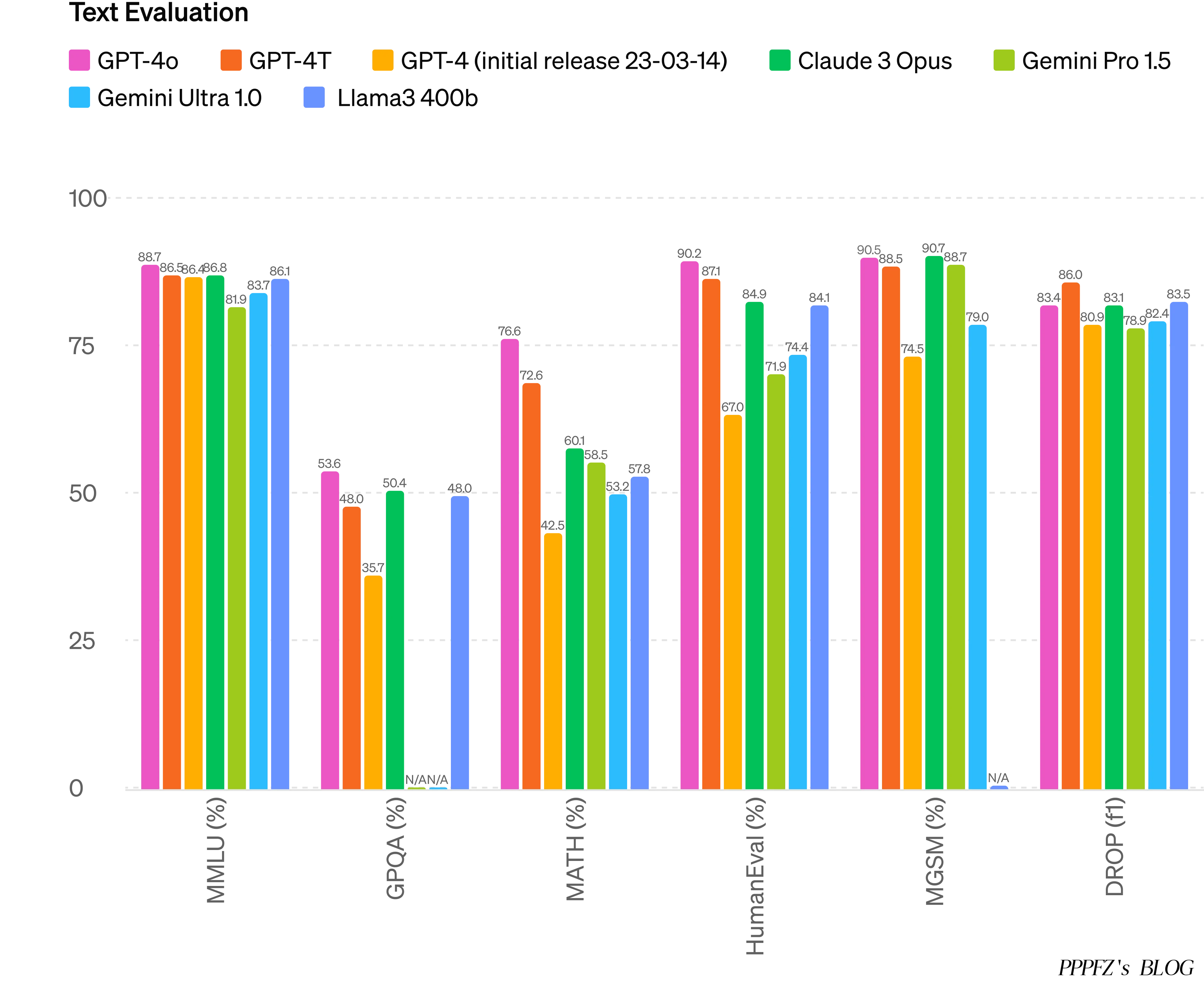
根据传统基准测试,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上设置了新的高水位线。
超级丝滑,逼真的对话
穆拉蒂补充说,它将对所有用户免费,付费用户将继续“拥有免费用户五倍的容量限制”。
OpenAI 在该公司的一篇博客文章中表示,GPT-4o 的功能“将迭代推出”,但其文本和图像功能将于今天开始在 ChatGPT 中推出。
OpenAI 首席执行官 Sam Altman 表示,该模型是“原生多模式”,这意味着该模型可以生成内容或理解语音、文本或图像中的命令。 Altman 在 X 上补充道,想要修补 GPT-4o 的开发人员将可以访问该 API,其价格是 GPT-4 Turbo 的一半,速度是 GPT-4 Turbo 的两倍。
作为新模型的一部分,ChatGPT 的语音模式即将推出新功能。该应用程序将能够充当像 Her 一样的语音助手,实时响应并观察你周围的世界。当前的语音模式更加有限,一次只能响应一个提示,并且只能处理它能听到的内容。
这里有趣的是,明天Google也将在同一时间召开发布会:
https://x.com/Google/status/1788980289412252013
